2017年7月26日下午,“2017政务数据治理与创新高端研讨会”在北京梅地亚中心多功能厅隆重召开。本次研讨会由中国信息通信研究院、中国社科院信息化研究中心、国脉数据研究院联合主办。国脉海洋常务副总经理王路燕出席会议并发布了《国脉数据基因3.0产品》,这也是本次研讨会的一大亮点,她提出数据基因3.0能够实现资源匹配、事项标准化、考核评估扥功能,同时通过配置事实目录,更新理想目录,促进政务数据治理与创新。

国脉海洋常务副总经理王路燕
以下是会议现场发言实录:
尊敬的各位来宾下午好,在这里分享一下国脉政府数据资产管理的经验,刚才也听了多位专家关于大数据具体应用的观点,数据基因产品作为底层基础性工作,主要做信息资源梳理、规范化等工作。
先解释下“数据基因”名字的由来。该词来源于生物上的基因,生物学中的基因是由四个碱基构成,这些碱基可以形成复杂的DNA,而数据基因是由0和1构成,通过不同组合,可以表达很多不同的信息,这就是生物基因与数据基因的共同之处。
数据基因,一方面表达了数据的具体特性,另一方面描述了不同数据之间的关联以及从旧数据到新数据的进化。
在数据基因产品从1.0(2017年2月15日正式发布)到3.0的发展过程中,国家不断推出新的政策文件,并开展了政务信息资源目录国家试点工作。我们紧紧围绕这些变化并结合实践工作来完善数据基因产品。数据基因产品从1.0到2.0只用了短短两个月,而3.0 是隔了半年才推出的,我们充分结合了各地的实践工作,该产品不是仅仅提出概念化的东西,还有各地经验的汇总。
一、三个版本发展历程
(1)数据基因1.0:资源模板、资产登记。我们首次提出“资源模板”。
(2)数据基因2.0:资产普查、数据元标准化、资产地图、公共数据字段池、数据模型。
(3)数据基因3.0:数据元标注、事项梳理、数据治理、理想目录与事实目录。“理想目录与事实目录”是数据基因3.0的新特点。
二、应用案例
(1)淮安市信息资源梳理
这是第一个落地应用的数据基因案例。借助信息资源模板,在一个月内快速梳理出淮安全市82个部门的信息资源,通过数据基因系统,由各部门进行核实、确认,快速建立全市信息资源体系。
(2)浙江省全口径公共数据资源梳理
这也叫“公共数据资源梳理”,因为它还包括企事业单位,并非只包括政府单位,其范围很大。依托17年电子政务项目预审的工作,开展全省项目独立预审单位的信息系统普查、“全省最多跑一次”事项普查(责任清单、权力清单)、信息系统实有数据普查等,同时借助系统开展事项标准、数据标准等工作。
(3)贵州省数据资产登记
根据《贵州省政府数据资产管理登记暂行办法》,开展贵州数据资产登记工作,对信息系统、硬件资产、软件资产、数据资产(围绕管理、保存、存储等角度)进行梳理,同时建立系统、硬件、软件、数据之间的关系图谱。除此之外,还有海南、四川、广东、宁夏等省。
三、数据基因3.0新功能和新价值
1.资源匹配
这也是数据基因3.0不同于数据基因2.0的地方。其应用主要包括模板匹配、数据元标注、标签化、预设模型等四个方面。
(1)模板匹配
系统上拥有丰富的模板资源,现在有省、市级部门各70个,标准化数据元10000项,核心数据集2000个。基于这些模板资源,部门登录后,系统可进行自定匹配,推送本部门的资源模板。用户也可以采用订阅模式,订阅某类资源模板。
借助关联导入功能,以任何一个结点为单位,能够建立数据元、数据集、业务事项之间的管理,并能以任何一个为单位进行关联。
(2)数据元标注
从业务、系统抽取过来的数据项,可进行匹配设置,根据匹配规则在数据元模板中依据中英文名称进行快速精准匹配。完全匹配上的可直接填充模板中的数据元相关内容,明确数据元数据类型、长度、精度等描述。具体包括以下几点:
一是规则制定。模板资源中拥有数据元近20000条,采集了公安、卫生、交通、民政等领域的数据元标准。
二是精准匹配。对业务、系统产生的数据元进行匹配设置,可快速在模板库中找到匹配的数据元。
三是快速填充。对数据元的中文名称、数据类型、数据长度等进行描述并快速填充。
(3)标签化
目前在做政务信息资源梳理时,最困难的是数据分级分类问题,国家政务信息资源分类为国家基础信息资源、主题政务信息资源、部门政务信息资源。小的数据元可以做标签,未来做某一专题时,可以在这些标签基础上设计主题,如输入“教育”,关于此专题的内容就可以全部检索出来。
可以从三个方面进行标签化:
一是按照业务条线进行标签化,包括教育、科技、司法、农业、地税、海渔、工商、旅游、综合治理等业务条线;
二是按照数据领域进行标签化,包括经济建设、环境资源、城市建设、道路交通、教育科技、文化休闲、民生服务、机构团体等数据领域;
三是按照资源主题进行标签化,包括人口、法人、空间地理、信用、证照等资源主题。
(4)预设模型
数据基因3.0产品预设模型有人口库模型和法人库模型。
一是人口库模型,围绕人的生命周期,预设人口库信息资源模型,涵盖人的基本信息、学籍信息、婚姻信息、死亡信息、资产信息、残疾信息、住宿信息、宗教信息、生活信息、参保信息、文化信息、交通信息等。
二是法人库模型,围绕法人的生命周期,涵盖法人基本信息、财务信息、资质信息、法人及股东信息、税务信息、业务信息、荣誉信息、监管信息等。
2.事项标准化
做事项标准化的原因是为了要把事项做具体,每个数据项权威来源部门是哪里?表格数据项是什么?字段来源是哪里?要将每一事项追踪到源部门。
实现事项标准化,首先需要部门、事项规范性编码,其次要做到证照、批文的规范化、材料的规范化等,最后是确认数据源部门。我们提供基础字段池,如人口、法人的权威字段,能够做到所有的材料规范化并确认材料来源部门等。
3.数据治理
数据基因3.0产品提供数据治理功能,主要体现在考核评估、诊断、项目管理三个方面。
(1)考核评估
资源梳理是一个长期过程,对共享方式、置机方式(前置机方式、EXCEL方式等)、报送范围、指标设计等都有要求。数据基因系统提供数据治理模块,针对不同地方实际需求,设计数据治理评估考核体系,通过人工与系统评估相结合的模式,对各部门信息资源情况进行考核,从数据管理的不同维度出发,促进数据资源管理可持续发展。
(2)诊断
审查信息系统,对字段设置、租用机房、系统未上云、僵尸系统(依据适用范围而定)、数据未归集系统(数据点对点共享)、孤岛系统等进行诊断。根据诊断规则的设定,系统自动对所有部门信息系统进行诊断,并给出诊断意见,同时,诊断意见可以为数据管理部门在进行信息化新建项目、运维项目审批时,提供参考性意见。
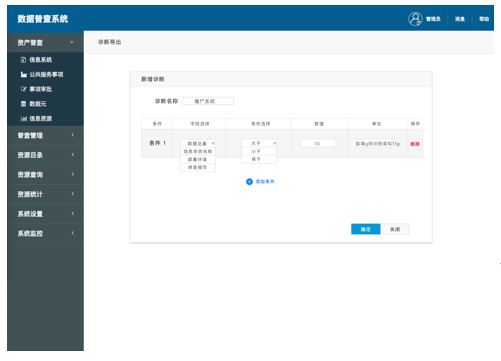
(3)项目管理
项目管理主要包括两类:一是新建项目,需提供新建项目的数据说明、新增数据等。二是延续项目,要关联相对应的应用系统名称,读取该应用系统的诊断报告,诊断该项目目前不适合延续或再提供运维费用(设置考核指标)。
4.理想目录-事实目录
理想目录是按照部门的职能要求应该具有的数据,事实目录是最终体现在共享交换平台上的数据,事实目录是基于理想目录对接过来的,二者是相互补充、相互融合的过程。数据字段是根据理想目录进行勾选并细化,最终会出现理想目录与事实目录的对比表,通过该表格,可以看出事实目录中没有的理想目录,主动找出原因。
四、下一步计划
一是建设数据元服务平台,整合现有的模板、标准化的资源,由各个用户参与数据元标准化工作;
二是开放知识图谱研究工作,目前在研究探讨中;
三是开展多领域应用,研发应用不同行业的版本。
五、优势
国脉拥有“咨询+产品”的优势,在信息化咨询服务中可以提供最好的产品,在产品中可以提供最好的咨询服务。










