实现数据的流动是构建“互联网+政务服务”体系的基础工作。从数据视图出发, 结合系统整合理论和“互联网+”核心特征, 以广州市网上办事大厅个人事项为数据源, 采用社会网络分析方法剖析数据资源的跨层级流动和使用。针对市级“互联网+政务服务”体系, 应综合考虑市、区县、镇 (街) 、村 (居) 层面的数据协同需求, 以市和区县两级为核心构建数据认可和数据协商机制、数据同步和数据比对机制、数据查询和数据反馈机制以及面向社会机构的数据导入机制。
实现数据的流动是构建一体化、协同化、精准化“互联网+政务服务”体系的基础工作, 让数据在各级政府、不同政府部门之间切实流转起来, 才能够真正做到让老百姓“少跑路”。2016年9月国务院提出“加快推进‘互联网+政务服务’工作”之后,很多地方政府提出一系列改革举措, 取得了一定经验, 例如浙江省推进“最多跑一次”改革, 贵州省提出了“五全服务”目标, 武汉市探索“马上办、网上办、一次办”模式。在此基础上, 国务院办公厅印发了《“互联网+政务服务”技术体系建设指南》, 旨在规范“互联网+政务服务”技术体系, 确保如期建成“互联网+政务服务”体系。与此同时, “以共享为原则、不共享为例外”也被确立为政务信息资源共享的第一原则。但是, 地方政府, 尤其是地市级以下政府, 在推进落实面向“互联网+政务服务”的政务信息资源共享时, 依然面临诸多挑战。正所谓“上面千条线, 下面一根针”, 在纵向系统数量众多和较为强势的背景下, 如何在地市级政府层面 (包含其下各级政府或机构) 真正实现数据的流动是目前亟需破解的难题之一。
针对政务信息资源共享问题, 围绕共享需求、制约因素、推进策略等方面, 学术界已经做了大量深入研究;在云计算提出之后, 还探究了基于政务云的政务信息资源共享机制和平台建设方案;并且开始关注“互联网+政务服务”的数据共享互通问题。然而, 依然存在以下需进一步深入研究的空间:一是尽管注意到了打通纵向系统的必要性和高难度, 但是总体而言针对“跨部门”共享的研究偏多, 针对“跨层级”共享的研究偏少;二是明确区分了“互联网+政务服务”与传统电子政务的不同, 但是在实际研究中对“互联网+”的“跨平台、多样性、高智能”等本质特征的关注不够;三是主要从业务层面和用户视角研究共享问题, 较少从系统层面和数据视图出发探析共享问题。
本文从数据视图出发, 并且结合系统整合理论和“互联网+”核心特征, 选取广州市网上办事大厅个人事项作为数据源, 采用社会网络分析方法深入剖析数据资源的跨层级流动和使用, 提出“互联网+政务服务”跨层级数据协同机制的构建思路。其中, 数据协同是指为了实现政务信息资源共享, 在整合相应政务信息系统时, 不同层级间政府和政府部门间协调配合完成对数据的定义、传输、存储、检索、分析、利用等工作。对于地方政府而言, 跨部门数据协同直接影响一体化政务服务的能力和质量;但是, 跨层级数据协同是跨部门数据协同的基础, 直接影响一体化政务服务的范围和深度。
一、研究设计
(一) 资料来源
在选择研究对象之前, 本文确立了三项标准:一是针对政府提供的个人服务事项, 这是让更多公众直接具有获得感的领域, 也应是各地推进“互联网+政务服务”的切入点;二是选择省会城市, 《“互联网+政务服务”技术体系建设指南》将“互联网+政务服务”平台体系分为国家级平台、省级平台、地市级平台三个层级, 直辖市过于特殊, 地市级城市的总体推进力度不如省会城市;三是对应的政府网站平台建设先进、公布的个人服务事项全面规范, 便于数据的采集, 由此确定以广州市网上办事大厅个人事项作为数据源。2016年10月11日, 广州市政府办公厅出台《广州市网上办事管理办法》, 对网上办事大厅的建设原则、组织机构及职责、网上服务业务办理等做出了明确规定;同时, 其网站平台建设也非常先进。
数据采集和处理的过程和方法主要参考龙怡和李国秋的论文, 但是增加“层级”要素, 包括四个步骤: (1) 数据采集, 登陆广州市网上办事大厅, 按照22个主题分类, 将全部的个人服务事项信息下载保存; (2) 层级归类, 根据受理单位的层级将个人事项划分到不同层级中, 即市级、区级、镇 (街) 级、村 (居) 级四个层级; (3) 事项去重, 对事项内涵一致、受理单位不同的同一事项进行去重处理, 仅保留其中1项; (4) 材料梳理, 对每个事项涉及的办事材料进行梳理, 包括规范、去重、编码、分类等。最终得到的各层级个人事项数量和办事材料数量 (参见表1) 。四个层级共有699项个人办事事项, 其中区级承担的个人事项最多, 有414项;区级个人办事事项所需要提供的办事材料数量也最多, 包括2781个;四个层级的个人办事事项平均需要提供办事材料6.90个。
表1 各层级个人事项数量和办事材料数量

(二) 研究方法
首先是运用社会网络分析方法对各层级数据流状况进行分析。社会网络图的构建以办事材料共同出现在同一个个人办事事项流程为依据, 将生成或提供办事材料的部门作为“来源节点”, 将受理或要求提供办事材料的部门作为“接收节点”;部门之间的办事材料流动越多, 它们之间的关联程度就会越高。接收部门的确定可以直接从采集得到的个人办事服务信息中获取;来源部门的确定, 不仅在采集到的个人办事服务信息查找对应事项, 还借助搜索引擎、询问相关工作人员等方式确定。标注来源部门和接收部门的层级, 作为部门类型, 具体分为省级以上部门 (含省属政府部门、国务院各部委、军队、海关、使馆等) 、市级部门、区级部门、镇 (街) 级部门、村 (居) 机构;对来自学校、医院、单位、个人等社会机构或个人的材料, 将其部门类型标注为“其他”。根据四个层级的个人办事事项, 分别整理出对应的邻接矩阵, 运用UCINET软件进行中心度分析。
接着, 将699项个人办事服务中所需要的全部办事材料作为数据资源, 从数据视图角度出发进行跨层级使用分析, 考察每个数据资源在各层级中的使用状况, 并且归纳汇总出具体的使用层级;结合数据资源跨层级使用的分布状况, 分析相应的跨层级数据协同需求。
最后, 则是基于各层级数据流状况和数据资源跨层级使用分析结果, 结合系统整理理论和“互联网+”核心特征, 构建“互联网+政务服务”的跨层级数据协同机制。
二、各层级个人事项数据流的社会网络分析
(一) 市级个人事项数据流的社会网络分析
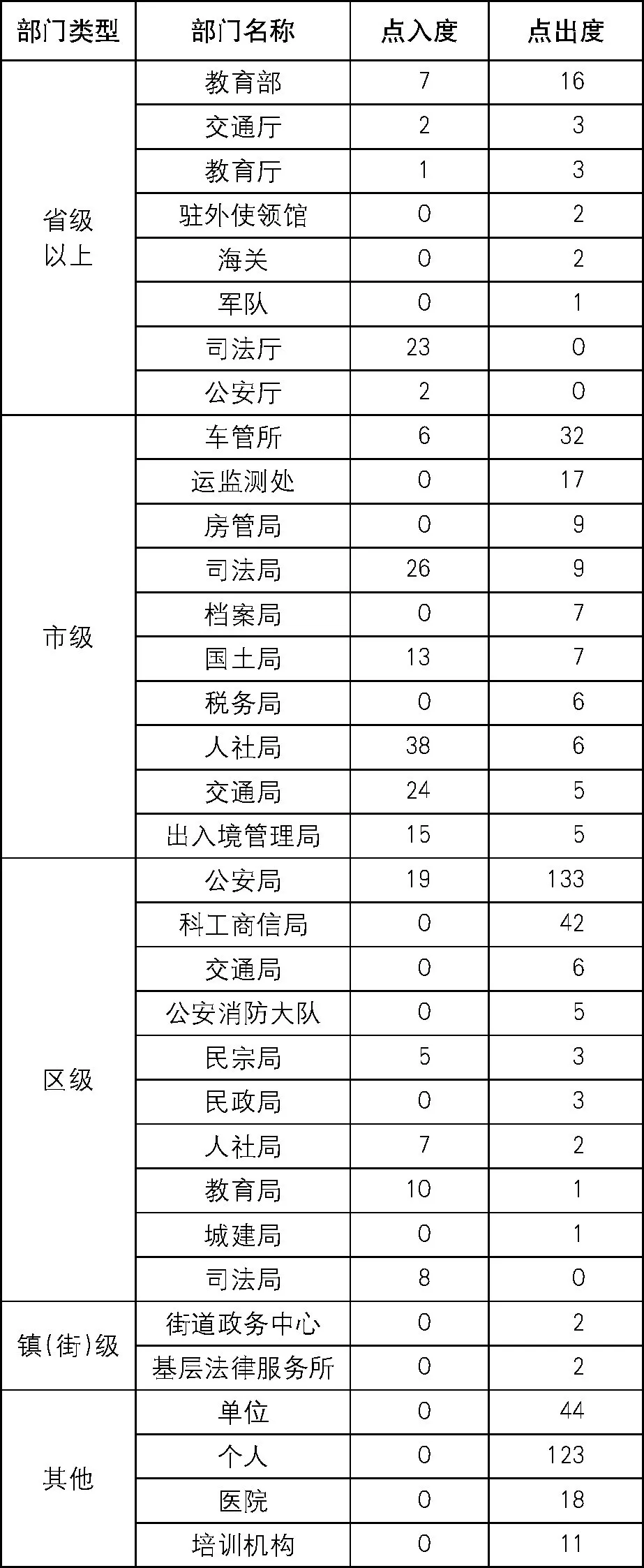
172项市级个人事项共涉及部门或机构98个, 形成98×98的邻接矩阵。其中省级以上部门21个, 市级部门46个, 区级部门15个, 街 (镇) 级部门2个, 其他机构14个。部分部门和机构对应节点的中心度见表2, 按照节点的出度降序排列。
对于办理市级个人事项而言, 不仅需要在市级各部门间流转材料, 而且需要从省级以上部门、区级部门、镇 (街) 部门、其他机构获取材料或提供材料。对其他部门或机构的材料需求大的部门 (点入度大的部门) 包括市人社局、市司法局、市交通局等。其他部门或机构对提供材料需求大的部门或机构 (点出度大的部门) 包括区公安局、个人、单位、区科工商信局等, 其中, 需要从区公安局获取材料的频率达到133次, 从区科工商信局获取的频率达到42次, 跨层级之间的数据流动非常明显。真正实现市级个人事项的精简, 例如“最多跑一次”, 跨层级数据协同很有必要。
表2 市级个人事项涉及部门的节点中心度
(二) 区级数据流的社会网络分析
414项区级个人事项共涉及部门或机构66个。其中, 省级以上部门7个, 市级部门13个, 区级部门31个, 镇 (街) 级部门5个, 其他机构10个。部分部门和机构对应节点的中心度参见表3。
表3 区级个人事项涉及部门的节点中心度
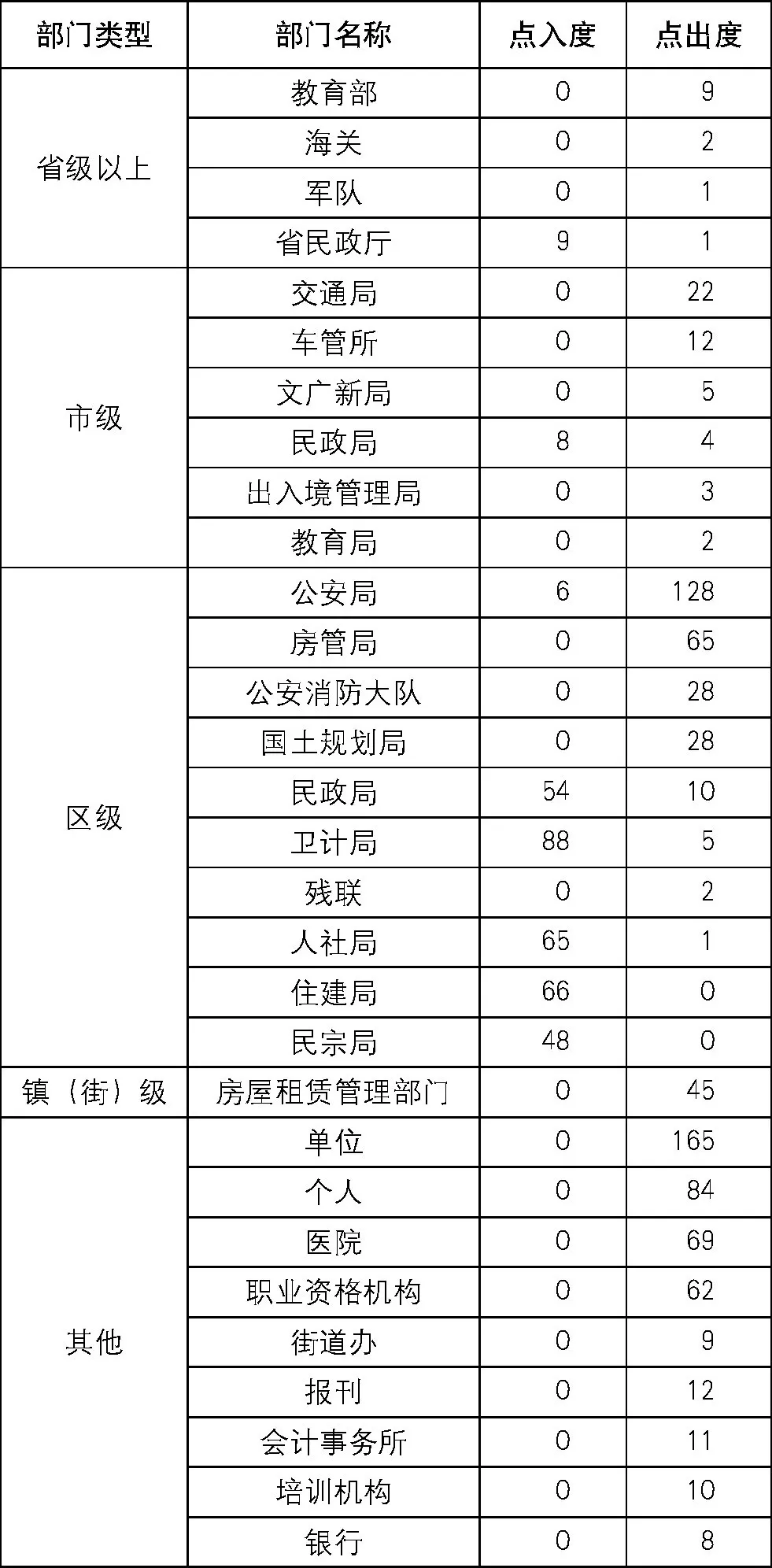
对于办理区级个人事项而言, 其数据协同需求存在三个明显特征: (1) 区级部门之间存在非常多的数据流动需求, 其中一些部门数据流出多 (区公安局、区房管局) , 一些部门数据流入多 (如区卫计局、区住建局、区人社局、区民政局等) ; (2) 需要市级部门、镇 (街) 部门获取大量材料用于事项办理, 起着承上启下的关键作用; (3) 需要从其他社会机构中获取大量材料, 包括单位、个人、医院、职业资格机构等。另外, 区级要完成的个人办事事项也是最多的, 达到414项, 因此在区级层面实现数据协同就显得十分必要。区级层面的数据协同应在满足区级部门之间数据流动需求的基础上, 向上对接市级部门, 向下对接镇 (街) 级部门, 同时还要建立与其他社会机构之间的数据对接通道。例如, 办理区级个人事项中需要从单位获取材料的频率达到165次, 从医院获取材料的频率达到69次。
(三) 镇 (街) 级数据流的社会网络分析
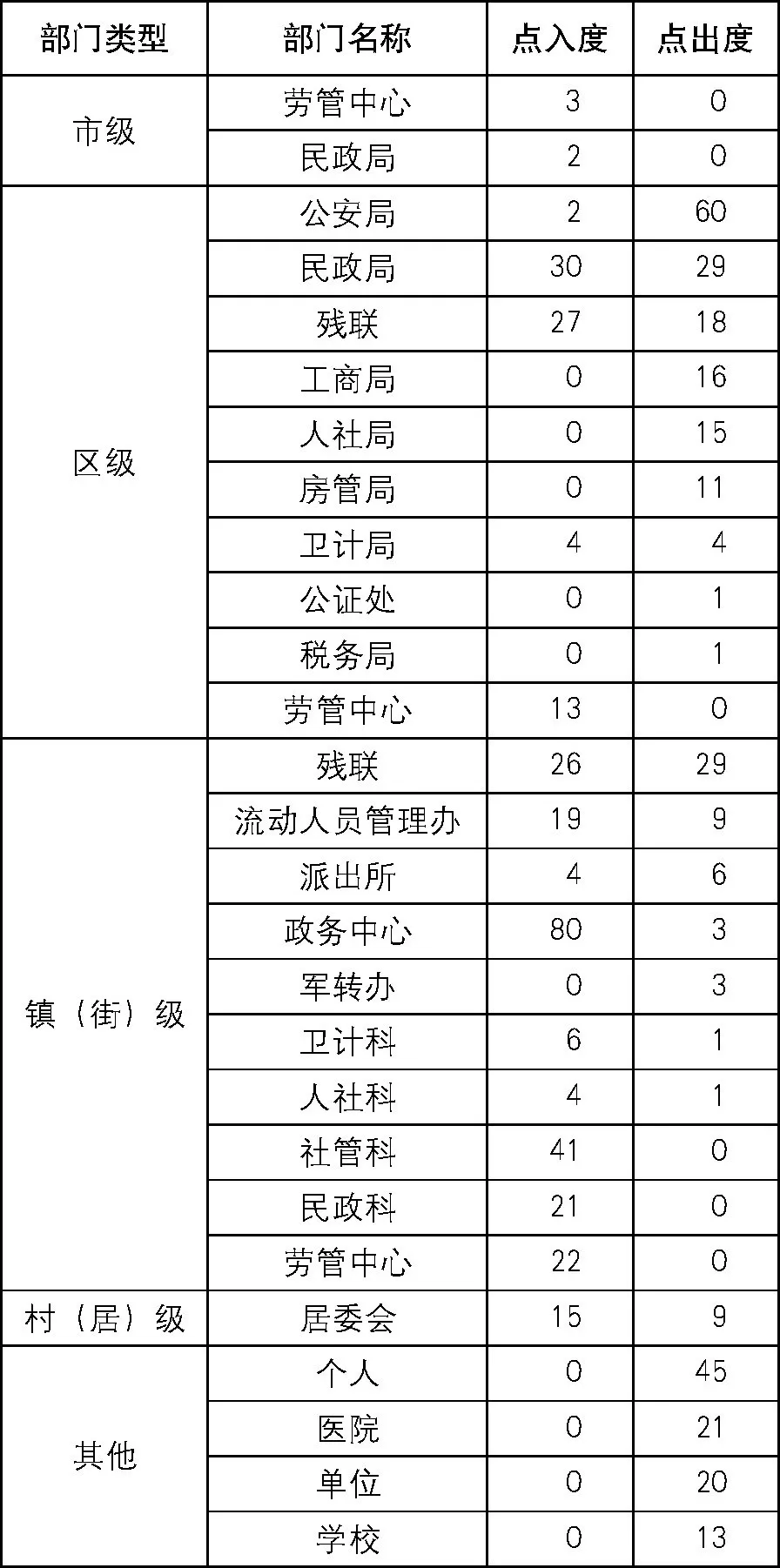
83项镇 (街) 级个人事项共涉及部门或机构43个。其中, 市级部门6个, 区级部门13个, 镇 (街) 级部门13个, 村 (居) 级1个, 其他机构10个。部分部门和机构对应节点的中心度见表4。
对于办理镇 (街) 级个人事项而言, 一方面需要在镇 (街) 级部门之间流转材料;另一方面则需要与区级相关部门之间流转材料, 镇 (街) 级部门与区级部门之间的数据流动较多。例如, 镇 (级) 级残联的流入和流出频率分别为26、29, 区级残联的流入和流出频率分别为27、18。进一步分析相关流程可以发现, 其中不少流转出现在镇 (街) 级和区级残联之间。另外, 也需要与村 (居) 委会、其他社会机构流转资料。
(四) 村 (居) 级数据流的社会网络分析
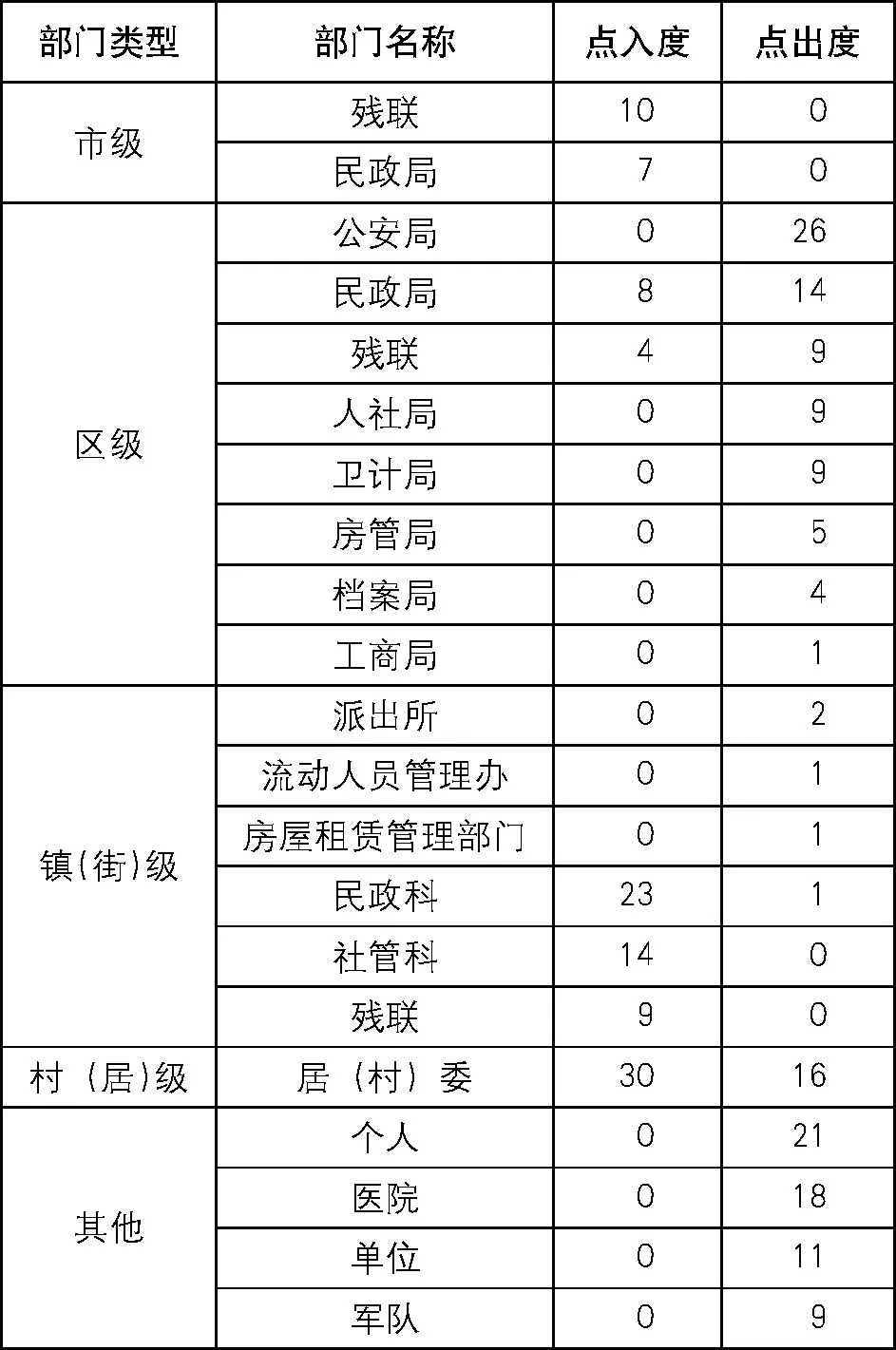
30项村 (居) 级个人事项共涉及部门或机构25个。其中, 市级部门2个, 区级部门10个, 镇 (街) 级部门7个, 居 (村) 委1个, 其他机构5个。部分部门和机构对应节点的中心度参见表5。
表4 镇 (街) 个人事项涉及部门的节点中心度
对于办理村 (居) 级个人事项而言, 一方面需要个人从区级政府部门或其他社会机构获取相关材料, 如区公安局、区民政局、区残联、区人社局、医院、单位等;另一方面, 作为代办机构, 需要向镇 (街) 部门提供相应的办事材料, 如镇 (街) 民政科、镇 (街) 社管科。
表5 村 (居) 个人事项涉及部门的节点中心度
三、数据资源的跨层级使用分析
根据办事材料在不同层级个人事项中使用的状况, 进一步梳理699项个人事项中涉及到的全部材料, 共识别出226份跨层级使用的数据资源 (参见表6) 。其中, 跨4个层级使用的数据资源有11份;跨3个层级使用的数据资源有81份, 包括跨“省以上—市—区”使用的39份、跨“市—区—镇 (街) ”的26份、跨“区—镇 (街) —村 (居) ”使用的16份;跨2个层级使用的数据资源有134份, 包括跨“市—区”使用的60份、跨“区—镇 (街) ”使用的32份、跨“镇 (街) -村 (居) ”使用的42份。具体而言, 数据资源的跨层级使用体现如下特征:
表6 数据资源的跨层级使用状况
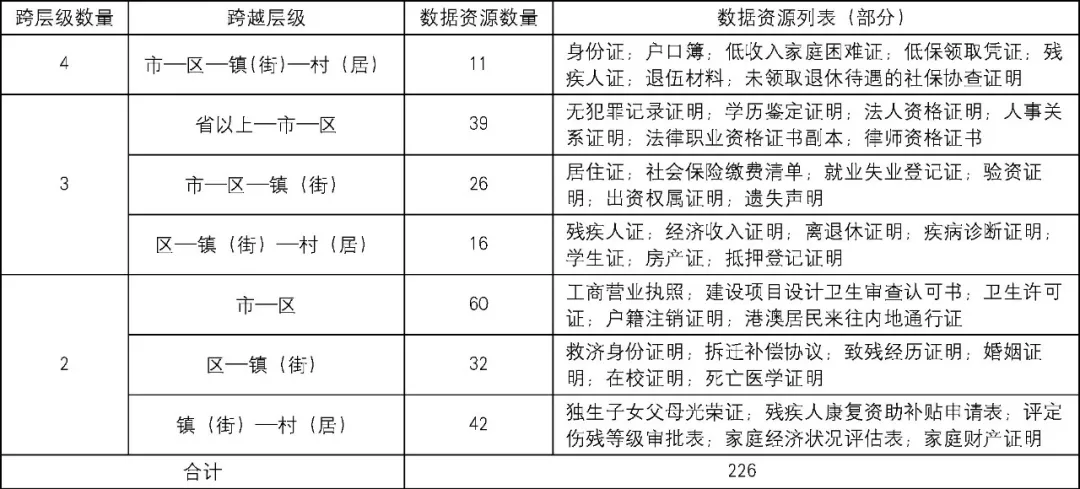
一是跨市级和区级两个层级的数据资源最多, 两者之间的数据协同任务重。只跨市级和区级的数据资源就有60份, 还有跨三级、跨四级使用中包含跨市级和区级的数据资源76份。这体现出区 (县) 级政府在我国行政管理体制中的任务分工, 不仅要接受地市级政府领导、完成相关事项, 而且直接面对公众提供大量公共服务事项。因此, 在市、区之间建立有效的数据协同通道和机制就非常重要。
二是涉及镇 (街) 这一级的跨层级使用数据资源也比较多。不论是跨四级使用的数据资源, 还是跨三级使用和跨两级使用的数据资源中, 都存在较多在镇 (街) 级层面使用的数据资源。这也表明, 镇 (街) 级相关部门以及在面向个人事项的办理中具有较大的作用。
三是从数据资源的来源部门看, 较多来自公安、民政、人社、卫计等领域。例如, 源于公安部门的身份证、户口簿、居住证等, 源于民政部门的婚姻证明、残疾人证、低收入家庭困难证等, 源于社保部门的社会保险缴费清单、就业失业登记证等, 源于卫计部门的独生子女父母光荣证等。另外, 还有不少来自其他社会机构的相关数据资源, 例如医疗机构的死亡医学证明、学校出具的在校证明等。
四是从数据资源的载体形式看, 证件和证明数量仍然居多。在“互联网+政务服务”快速发展的大背景下, 尽管公众可以直接从政府网站上查到办事指南、办事流程、办事机构、办事地点, 可以在线咨询相关工作人员, 甚至在线下载和提供相关资料完成部分或全部办理流程, 但是依然面临着提供大量证明材料的局面, 数据协同的进展还很不理想。
四、“互联网+政务服务”跨层级数据协同机制
根据各层级数据流动分析结果和数据资源的跨层级使用特征, 本文认为应综合考虑市、区县、镇 (街) 、村 (居) 层面的数据协同需求, 在跨层级协同构建上应以市和区县两级为核心, 原因在于:一是市和区县两级之间的跨层级数据协同需求最大;二是镇 (街) 一级的跨层级数据资源也比较多, 完全由市级层面协调难度较大。因此, 应构建市、区 (县) 两级互联网政务服务门户;对于市级政务服务数据共享平台而言, 也可以构建分布式的区县级分中心, 负责实现和满足本区域的政务数据协同需求。“互联网+”的核心特征至少包括跨平台、多样性、高智能三个方面, 在构建“互联网+政务服务”体系时, 应联通所需要的各个平台、接受并利用平台和数据的多样性, 同时应充分发挥智能分析的作用。基于上述分析, 本文提出的“互联网+政务服务”跨层级数据协同机制如图1所示。
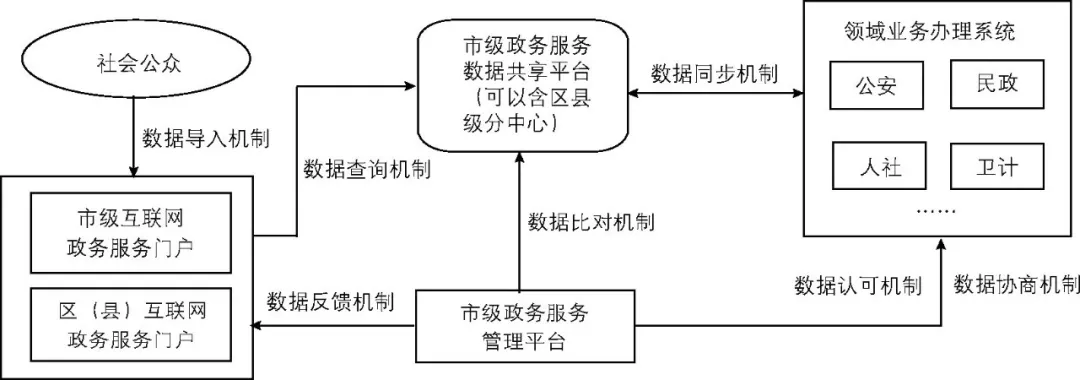
图1“互联网+政务服务”跨层级数据协同机制
(一) 数据认可和数据协商机制
实现“互联网+政务服务”跨层级数据协同的第一步, 也是最为关键的一步, 可以从公安、民政等领域率先开始。应从市级政府层面出发构建与各个领域业务办理系统的数据认可和数据协商机制, 实现领域系统对同一服务对象的同一数据相互认可;当出现不一致的时候, 能够相互协商、达成一致。这里面存在大量跨层级协调问题, 一方面是由于办事事项本身存在层级性;另一方面是相关系统的建设者也存在层级性。如果由区县级政府层面实施协调, 难度实在太大, 也没有必要。没有数据认可和数据协商机制, 就难以跨越部门办事服务需要提供大量证明文件的“鸿沟”, 也难以应对数据交换共享之后出现的大量数据不一致的局面。
(二) 数据同步和数据比对机制
在具备了数据认可和数据协商机制之后, 就能够实现市级政务服务数据共享平台与领域业务办理系统的数据同步, 并且进行数据比对分析。因此, 需要构建相应的数据同步和数据比对机制。实现了数据同步和比对分析, 才能够让数据在相关系统中自由流动, 并快速找到数据之间出现的矛盾和不一致, 让公众体验到平台的“智慧”所在且感到满意, 真正体现“互联网+政务服务”的高智能, 发挥众多平台的各自所长。
(三) 数据查询和数据反馈机制
在面向社会公众的数据应用上, 主要是基于市、区 (县) 两级互联网政务服务门户。由市级政务服务管理平台构建相应的数据查询和数据反馈机制, 满足市、区 (县) 两级互联网政务服务门户的数据协同需求。互联网政务服务门户本身不与领域业务办理系统交换数据, 而是通过市级政务服务数据共享平台实现对相关数据的查询需求。
(四) 面向社会的数据导入机制
针对办事服务中需要从社会机构或个人获取大量数据资源的状况, 应在市、区 (县) 两级互联网政务服务门户上构建便捷、可机读、可存储的数据导入机制, 为公众提供相应的电子化通道。可以率先实现对相关数据材料的线上审核, 通过后再提交对应的纸质文件。
五、结束语
以大数据为代表的新一代信息技术为构建更加便捷和智能的政务服务体系提供了新的可能, “互联网+政务服务”应运而生。但是, 实现数据在各层级政府部门之间、政府部门与社会机构顺利流动并非易事。本文以广州市网上办事大厅个人事项为数据源, 采用社会网络分析方法剖析了数据资源的跨层级流动和使用, 初步构建“互联网+政务服务”跨层级数据协同机制, 对推动地方政府推进“互联网+政务服务”体系建设具有重要参考价值。当然, 本文也存在不足, 主要有两点:一是仅从个人事项出发, 对企事业单位办事服务未作分析;二是将各领域业务办理系统统一进行考虑, 未对它们之间的复杂关系进行深入分析。在未来研究中, 将进一步针对上述不足, 选择合适的研究对象展开相关研究。










